Playing CHESS with stars I: Search for similar stars in large spectroscopic data sets
This work presents a procedure that significantly simplifies the identification of spectra from stars with similar atmospheric parameters within extensive spectral datasets.
Massive amounts of spectroscopic data obtained by stellar surveys are feeding an ongoing revolution in our knowledge of stellar and Galactic astrophysics. Analysing these data sets to extract the best possible astrophysical parameters on short time scales represents a considerable challenge. The differential analysis method is known to return the most precise results in the spectroscopic analyses of F-, G-, and K-type stars. However, it can only be applied to stars with similar parameters. In this publication, we describe a method that allows for the quick application of differential analyses in these samples, thus enhancing the precision of the results. This method is implemented in the "similarity analysis" module of the CHESS pipeline.
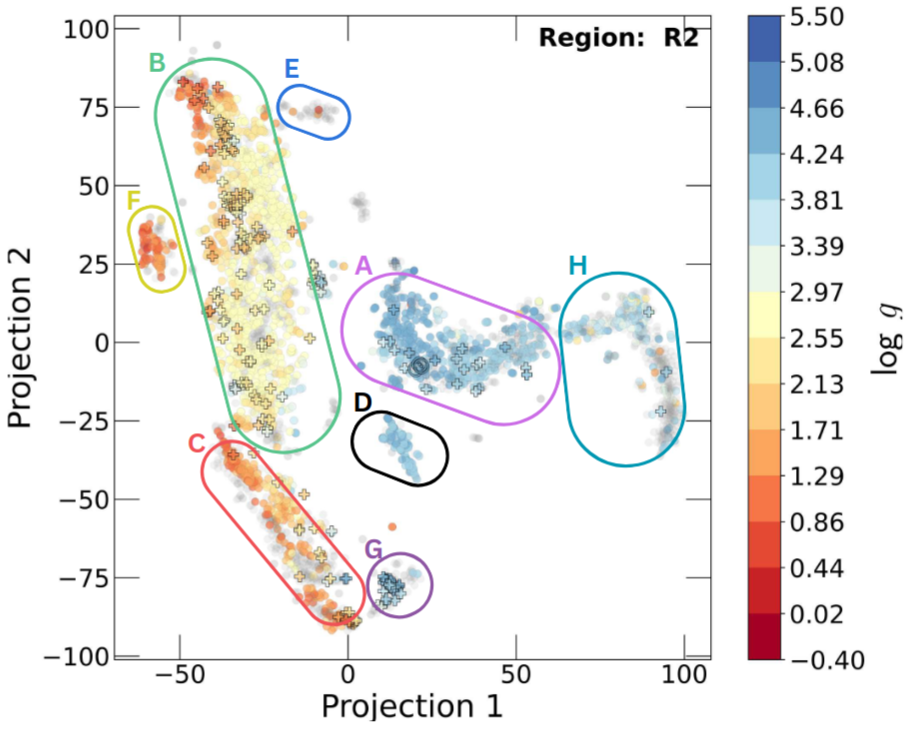
Figure 1: Example of a 2D projection map of stellar spectra obtained using t-SNE. The points are colour-coded by the atmospheric parameters of the stars taken from the Gaia-ESO Survey catalogue. Region A contains FGK-type dwarfs. Region H contains early-type dwarfs. Regions B and C contain metal-rich and metal-poor giants, respectively. This figure is the mid panel of Fig. 4 in the publication.
In this study, we present and discuss our method for finding similar stars based purely on their spectra. The method makes use of the dimensionality reduction algorithm known as t-SNE. We consider that each spectrum is a point in a multidimensional space with pixels as dimensions and their flux as coordinates. Within this space, data points representing similar spectra cluster together. With t-SNE we want to create a projection map of these data in two dimensions (2D). An example of 2D projection is shown in Fig. 1. The performance of the method was tested and calibrated using catalogues of atmospheric parameters available in the literature.
What Did We Find?
The main points of our method are:
- We calibrated a metric focused on spectra similarities that allows the identification of similar spectra surrounding a given reference in the projection map. The stars identified in this way have parameters within 200 K in Teff , 0.3 dex in log g, and 0.2 dex in [Fe/H]. The similarity threshold can be adjusted depending on the balance between completeness and purity needed in the selection.
- Tests using our own differential analysis showed that with our choice of spectral metric, we can achieve completeness between 74-98 % and typical purity between 39-54%.
- This analysis to identify similar stars is a crucial step in the CHESS pipeline. It will enable efficient selection of target stars for precise differential analysis.
Why Does This Matter?
Stellar spectra encode information on properties such as detailed surface chemical abundances, rotation, magnetic activity, and mass accretion or loss. Having such data for large samples of stars of different ages, formed in a wide variety of environments, is essential to clarify the origins of the elements, the formation and evolution of planets and stars, and to better understand the complexities of the formation and evolution of the Milky Way.
Recognising this need for extensive spectroscopic data, several large stellar spectroscopic surveys have been designed and are now feeding an on-going revolution in stellar and Galactic astrophysics. With spectra available for tens of millions of stars, the challenge shifts to efficiently analysing the data on short timescales while maintaining the high quality of the results. This can only be attempted by automatic routines and pipelines.
Among the different implementations of the traditional approach to spectroscopic analysis, the differential method produces the most precise results. In a differential analysis, stars of similar atmospheric parameters are analysed with respect to each other. In such a comparison, the systematic errors are assumed to be the same and to cancel out. In this case, the differences in parameters and abundances are determined with very high precision.
With this motivation, we are developing a new pipeline called CHESS (CHEmical Survey analysis System) which aims to derive precise, accurate, and complete chemical information from large samples of spectra of F-, G-, and K-type stars. It uses the differential analysis method for high precision and a set of reference stars to anchor the parameter scale with high accuracy. To identify similar stars for differential analysis, CHESS is using the method described in the publication for a similarity analysis using directly the spectra before any radiative transfer analysis.
Our method drastically facilitate the detection of stars with similar spectra for a successful differential analysis, and will help to guarantee that the best possible results are extracted from the large databases of stellar spectra currently being assembled by several projects.